chainer で Auto Encoder
久々の投稿です...、久々に研究の方に戻ってきたので、リハビリがてらブログの方もまた少しずつプログラムのこととか書いていきます。 今回もまた chainer ネタが続きますが、いままで Auto Encoder を使ったことがなかったので、試しにどんなものかなと...。
https://github.com/ShigekiKarita/chainer-autoencoders
元ネタは https://blog.keras.io/building-autoencoders-in-keras.html。 chainer も Trainer とか入って Keras っぽくなりましたけど、まだ Keras の方が楽そうですね。今回は少しややこしい学習をするので Trainer を使いませんでした。目的関数 (binary cross entropy) の学習経過です。
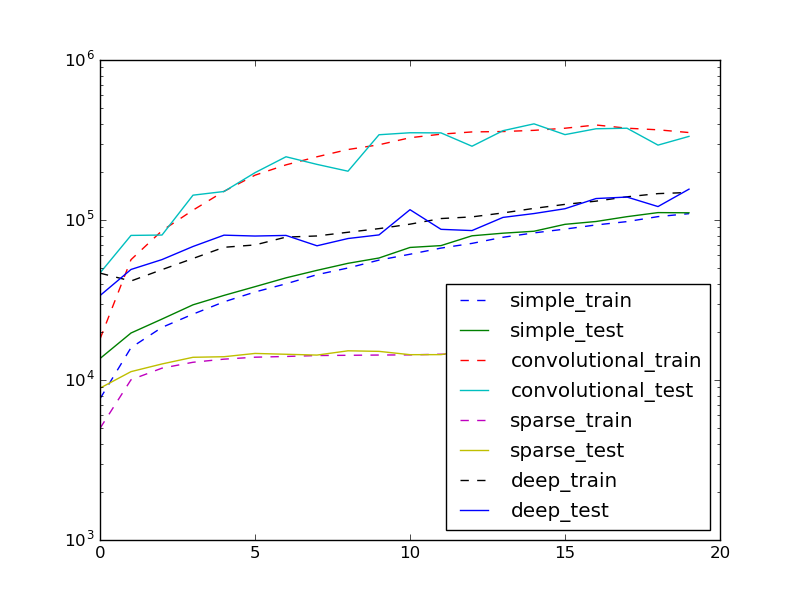
chainer は Chain の持つ add_link メソッドを使うと簡単にパラメタが追加できて便利です。他のライブラリなら一度シリアライズして、新しいモデルを作って初期値に読み込んで...といったディスクIOや構築のオーバーヘッドをなくせます。上の図のdeepは以下のコードです
class DeepAutoEncoder(AutoEncoderBase):
def __init__(self, n_in, n_depth=1, n_units=None):
super(DeepAutoEncoder, self).__init__()
self.n_in = n_in
self.n_units = n_units
self.encode_label = "encode%d"
self.decode_label = "decode%d"
self.n_depth = 0
self._init_layers(n_depth)
def encode(self, x):
for n in range(self.n_depth):
x = F.relu(self[self.encode_label % n](x))
return x
def decode_bottleneck(self, z):
for n in reversed(range(1, self.n_depth)):
z = F.relu(self[self.decode_label % n](z))
return self[self.decode_label % 0](z)
def _init_layers(self, n_depth):
first = None
if self.n_units:
first = self.n_units * (2 ** (n_depth - 1))
self.add_layer(first)
for n in range(1, n_depth):
self.add_layer()
def encoded_size(self):
if self.n_depth == 0:
return self.n_in
last = self.n_depth - 1
encode_last = self[self.encode_label % last]
return encode_last.b.data.size
def add_layer(self, n_out=None):
i = self.encoded_size()
o = i // 2 if n_out is None else n_out
self.add_link(self.encode_label % self.n_depth, F.Linear(i, o))
self.add_link(self.decode_label % self.n_depth, F.Linear(o, i))
self.n_depth += 1add_layer を呼ぶと、エンコードとデコード用で2層追加します。GPUを使っている場合は to_gpu() を更に呼ばないと怒られます (雑)。
あと、ちょっと前に職場で、学習過程の一連の図を動画にしたい...と言われて imageio というライブラリを紹介したんですが、あまりネットに情報がなかったのでコード片をメモすると
from os import path
from glob import glob
import imageio
def plot_movie(path):
# path には 001.png, 002.png ... みたいな画像がある
ps = glob(path + "/*.png")
ps = sorted(ps)
imgs = map(imageio.imread, ps)
# 内部の ffmpeg 等がサポートしている幅広い動画フォーマットが使える
writer = imageio.get_writer(path + "/test.gif", fps=4)
for i in imgs:
writer.append_data(i)
writer.close()ところで、gif動画って昔からありますけど、凄いサイズ大きいんですね。Twitterとかgif動画あげるとmp4にされますし、もうベストはmp4で良いんでしょうか。 さて学習の結果ですが、これが真値 (未学習データ)
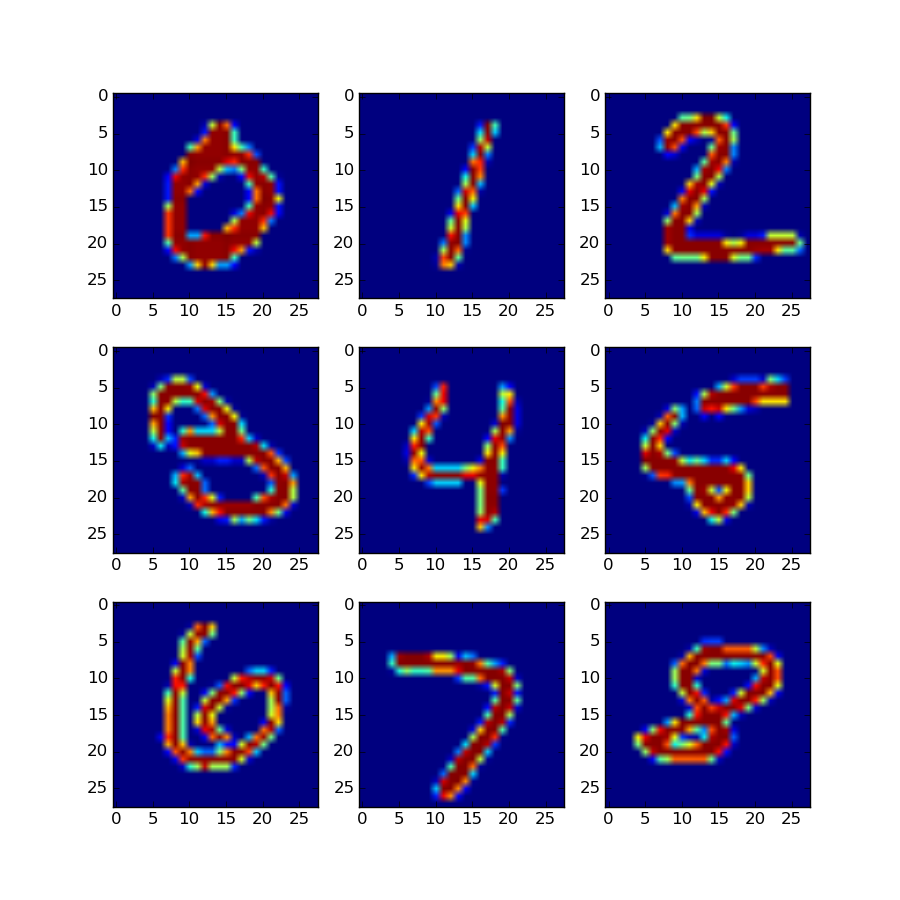
に対して、2層の AE だと、少しザラザラした感じがします
4エポックに2層づつ追加した8層の場合、新規層が追加されたエポックではまだ収束してなくてブワッと文字が広がるのが面白いですね。
あとかなりスコアの高い convolutional な AE は結構ほかと違う過程がでて、これも面白いです。
今回 AE は Python で OOP する良い題材になるかと思ったのですが、動的型付だとメソッド持ってればいいし、コンテナに入れる時も困らないのでis-a 関係などがフワっとして単なる差分プログラミングになってしまいました...。そもそもOOPって動的型付け言語(smalltalk)発祥だったのに、全然ベストプラクティスわからないし、文法が気持ち悪いのでなんだか smalltalk にちょっと興味出てきました^^;
Python に関してはtype(a) is Aとisinstance(a, A)って一緒だっけとか。出力に疎な罰則を加えたり、入力に雑音乗せるのは継承で別クラス作らなくても、関数用意してやればいい??...とか難しいです。それと久々にPython書くとスコープのシステムが最悪で、関数とモジュールしか作らないとか、色んな落とし穴踏み抜いて辛いです。